GoT’s novelty lies in its ability to apply transformations to these thoughts, further refining the reasoning process. The cardinal transformations encompass Aggregation, which allows for the fusion of several thoughts into a consolidated idea; Refinement, where continual iterations are performed on a singular thought to improve its precision; and Generation, which facilitates the conception of novel thoughts stemming from extant ones. Such transformations, with an emphasis on the amalgamation of reasoning routes, deliver a more intricate viewpoint relative to preceding models like CoT or ToT.
Furthermore, GoT introduces an evaluative dimension through Scoring and Ranking. Each individual thought, represented by a vertex, undergoes an assessment based on its pertinence and quality, facilitated by a designated scoring function. Importantly, this function contemplates the entire chain of reasoning, assigning scores that might be contextualized vis-a-vis other vertices in the graph. The framework also equips the system with the competence to hierarchize these thoughts predicated on their respective scores, a feature that proves instrumental when discerning which ideas warrant precedence or implementation.
Maintains a single evolving context chain, eliminating the need for redundant queries as in the Tree-of-Thought. It explores a mutable path of reasoning.
While ToT and GoT address the LLM reasoning challenge through search-based mechanisms, producing a myriad of reasoning paths in graph forms. However, their heavy reliance on numerous LLM queries, sometimes numbering in the hundreds for a singular problem, poses computational inefficiencies.
The Algorithm-of-Thoughts (AoT) offers an innovative method that features a dynamic and mutable reasoning path. By maintaining a single evolving thought context chain, AoT consolidates thought exploration, enhancing efficiency and reducing computational overhead.
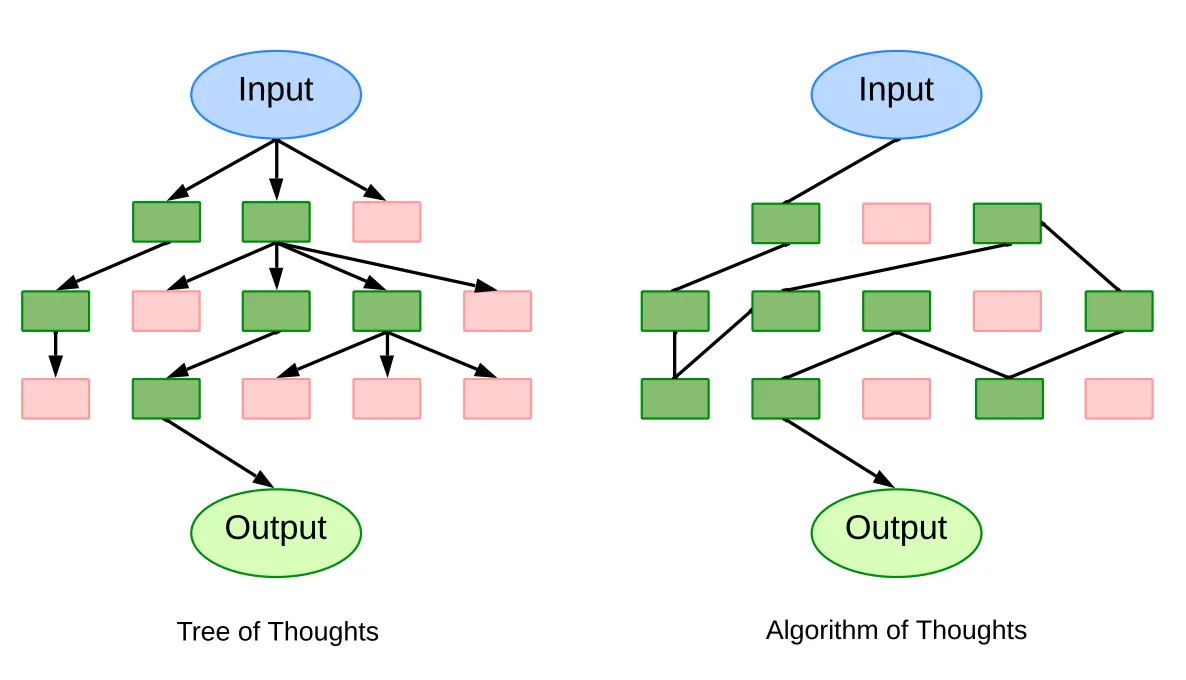
The ingenuity behind AoT springs from the observation that LLMs, although powerful, occasionally revert to prior solutions when faced with new yet familiar problems. To overcome this, AoT assimilates in-context examples, drawing from time-tested search algorithms such as depth-first search (DFS) and breadth-first search (BFS). By emulating algorithmic behavior, AoT underscores the importance of achieving successful outcomes and gleaning insights from unsuccessful attempts.
The cornerstone of AoT lies in its four main components: 1) Decomposing complex problems into digestible subproblems, considering both their interrelation and the ease with which they can be individually addressed; 2) Proposing coherent solutions for these subproblems in a continuous and uninterrupted manner; 3) Intuitively evaluating the viability of each solution or subproblem without relying on explicit external prompts; and 4) Determining the most promising paths to explore or backtrack to, based on in-context examples and algorithmic guidelines.
Generate an answer blueprint first before parallelly fleshing out the details, reducing the time taken to generate a complete response.
The Skeleton-of-Thought (SoT) paradigm is distinctively designed not primarily to augment the reasoning capabilities of Large Language Models (LLMs), but to address the pivotal challenge of minimizing end-to-end generation latency. The methodology operates based on a dual-stage approach that focuses on producing a preliminary blueprint of the answer, followed by its comprehensive expansion.
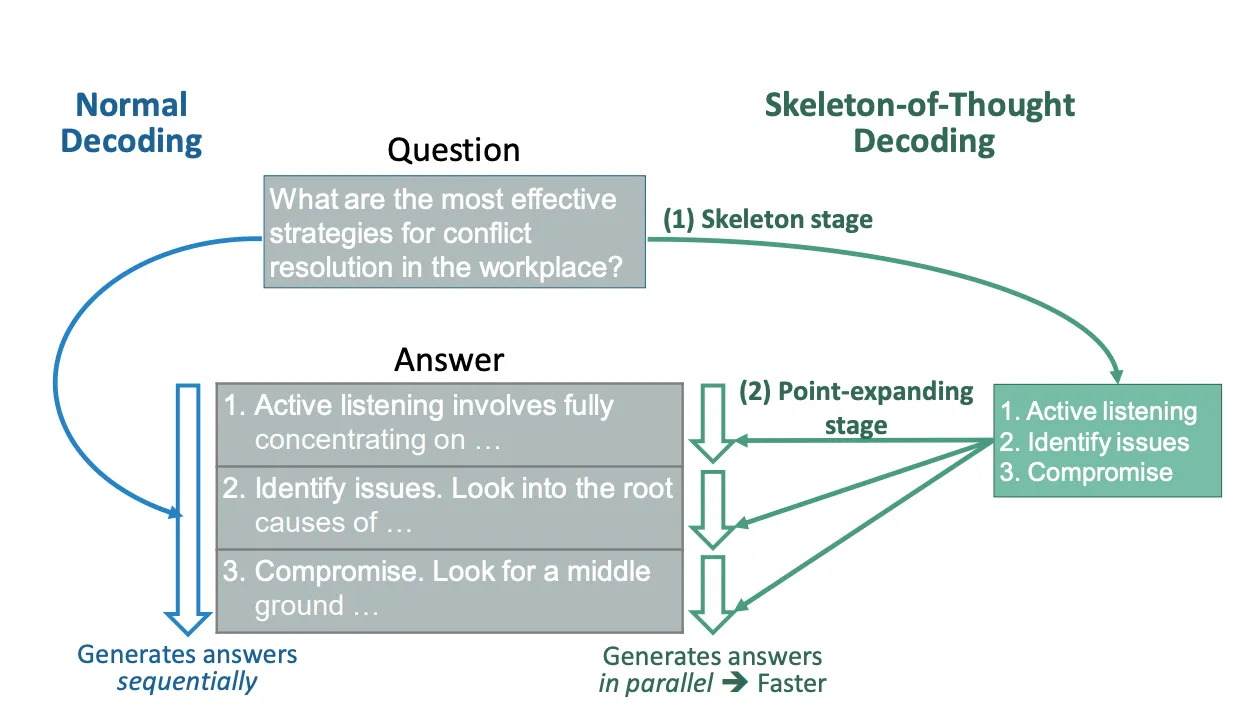
In the initial “Skeleton Stage,” rather than producing a comprehensive response, the model is prompted to generate a concise answer skeleton. This abbreviated representation prompted through a meticulously crafted skeleton template, captures the core elements of the prospective answer, thus establishing a foundation for the subsequent stage.
In the ensuing “Point-Expanding Stage,” the LLM systematically amplifies each component delineated in the answer skeleton. Leveraging a point-expanding prompt template, the model concurrently elaborates on each segment of the skeleton. This dichotomous approach, which separates the generative process into preliminary skeletal formulation and parallelized detailed expansion, not only accelerates response generation but also strives to uphold the coherence and precision of the outputs.
Formulate the reasoning behind question answering into an executable program, incorporated the program intepretor output as part of the final answer.
Program-of-Thoughts (PoT) is a unique approach to LLM reasoning, instead of merely generating an answer in natural language, PoT mandates the creation of an executable program, which means it can be run on a program interpreter, like Python, to produce tangible outcomes. This method stands in contrast to more direct models, emphasizing its ability to break down reasoning into sequential steps and associate semantic meanings with variables. As a result, PoT offers a clearer, more expressive, and grounded model of how answers are derived, enhancing accuracy and understanding, especially for math-type logical questions where numerical calculations are needed.
It is important to note that the program execution of PoT is not necessarily targeting the final answer but can be part of the intermediate step to the final answer.

This post originally appeared on TechToday.